
Usage
Here’s a simplified overview of the workflow that helmize goes through in order to render files. Understanding the workflow might help with the different usage topics, since they are referenced below in which step they become relevant.
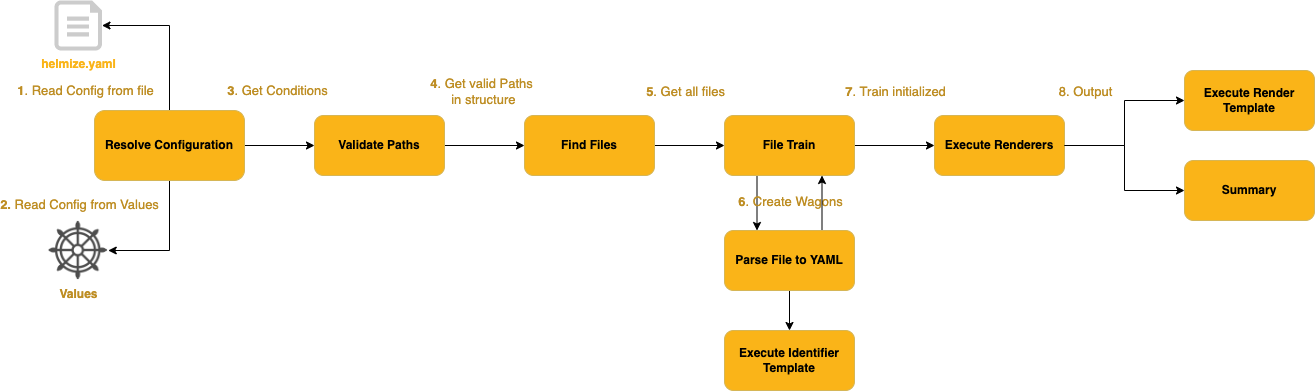
To give a bit more context:
- 1/2: To initialize Helmize tries to resolve to configuration that is used. If the configuration is valid Helmize will fail with an indicating error.
- 3: The resulting conditions extract based on the given configuration Data and paths which will be lookedfor potential files.
- 4: Based on the given paths, files are looked up. Only files which are not in the
templates/folder of the chart can be looked up. That’s why the structure is outside of the templates folder. - 5: Once all files are collected (just the paths) the so called file train is initialized. The file train has wagons, which are representative for resulting files.
- 6: Each file is now parsed. First it’s split into partial files, this is used for multi yaml support. then each partial file is evaluated. Based on the file’s config each partial file is created/merged into a wagon within the file train. To identify how the wagons are identified, the identifier template is used. Based on the identifiers of a partial file and other configurations it’s added to the file train. This loop is execute until all partial files from all paths are converted/applied into/to wagons.
- 7: The file train is initialized, now Renderers are executed, to enrich all the wagons after they are processed.
- 8: The file train is rendered as yaml. That’s defined in the Render Template. There are other output options via flags
And that’s all it does.